


Một trong những điều bạn cần phải kiểm tra và tối ưu hóa trong Technical SEO của bạn là file Robots.txt. Bởi vì. file Robots.txt sẽ giúp bạn kiểm soát các tệp không mong muốn mà trình thu thập dữ liệu có thể truy cập trên wibsite của bạn. Bằng cách chặn hoặc cho phép một trình thu thập dữ liệu truy cập vào một đường dẫn tệp được chỉ định cụ thể. Vậy Robots.txt file là gì? Cách sử dụng file Robots.txt cho Website của bạn như thế nào? Hãy cùng theo dõi với chúng tôi để hiểu hơn về vấn đề này nhé!
Mục Lục
Tổng quan về File Robots.txt
File Robots.txt là gì?
File Robots.txt là một tập tin văn bản đơn giản được sử dụng trong quản trị website. Tệp này là một phần của Robots Exclusion Protocol (REP) chứa một nhóm các tiêu chuẩn về web theo quy định. Trên thực tế, công dụng Robots.txt giúp các nhà quản trị web link hoạt và chủ động hơn trong việc kiểm soát bọ của Google.
Cách thức hoạt động của file Robots.txt
- Crawl-Delay: thông số này xác định thời gian (tính bằng giây) bots phải đợi trước khi chuyển sang phần tiếp theo. Điều này sẽ có ích để ngăn chặn các Search Engine load server tùy tiện.
- Ký tự # đánh dấu điểm bắt đầu của một nhận xét.
- Robots.txt hoạt động bằng cách xác định một User-agent và một lệnh cho User-agent này.
- Các tham số có trong file Robots.txt.
- Disallow: là khu vực mà bạn muốn khoanh vùng không cho phép Search Engine truy cập.
- User-agent: khai báo tên Search Engine mà bạn muốn điều khiển.
Hướng dẫn tạo file Robots.txt hiệu quả cho trang của bạn
Bạn có thể sử dụng hầu hết mọi trình chỉnh sửa văn bản để tạo tệp Robots.txt. Ví dụ: Notepad, TextEdit, Vim và Emacs có thể tạo các tệp Robots.txt hợp lệ. Đừng dùng trình xử lý văn bản vì trình xử lý văn bản thường lưu tệp dưới một định dạng độc quyền và có thể thêm những ký tự không mong muốn (chẳng hạn như dấu ngoặc kép cong). Việc này có thể khiến trình thu thập dữ liệu gặp sự cố.
Trong file này bạn sẽ viết những cú pháp nhất định để thể hiện mục đích của bạn. Một số cú pháp phổ biến được sử dụng bao gồm:
- User-agent: tên loại bot muốn áp dụng.
- Disallow: không cho phép loại bot có tên trong mục User-Agent truy cập vào website.
- Allow: cho phép bot được truy cập và thu thập dữ liệu.
- Dấu *: áp dụng cho tất cả mọi trường hợp.
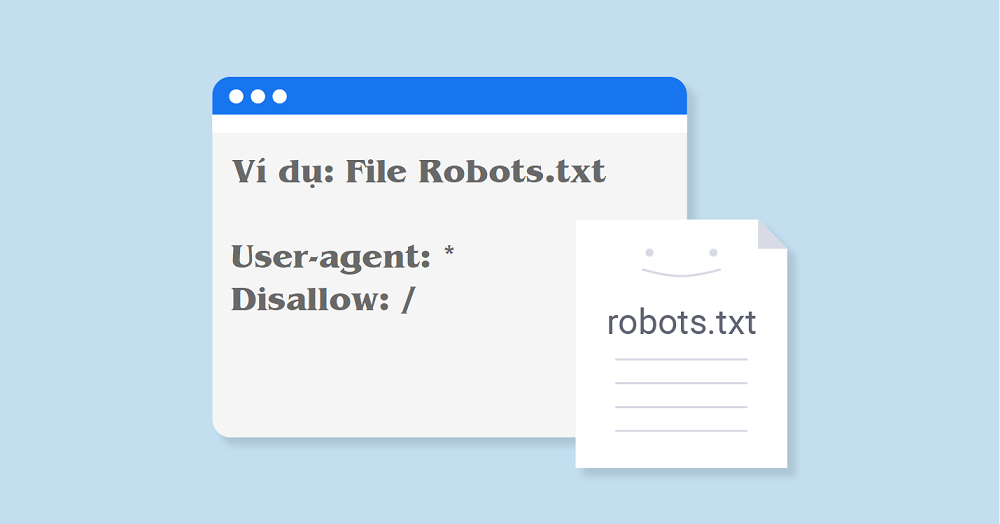
Ghi chú: Nếu bạn muốn áp dụng với tất cả thì sử dụng dấu *. Đối với mỗi một loại công cụ thu thập dữ liệu sẽ đều có một cái tên cụ thể. Chẳng hạn như Googlebot, Bingbot, Coccocbot… Nếu muốn chặn bất kỳ một loại bot cụ thể nào thì chúng ta sẽ khai báo tên của loại bot đó.
Các quy tắc sử dụng file Robots.txt bạn cần biết
Không cho phép thu thập dữ liệu toàn bộ trang web
Xin lưu ý rằng trong một số trường hợp, Google vẫn có thể lập chỉ mục các URL thuộc trang web mặc dù chưa thu thập dữ liệu những URL đó.
- User-agent: *
- Disallow: /
Không cho phép thu thập dữ liệu trên một trang của trang web
Ví dụ: không cho phép trang useless_file.html.
- User-agent: *
- Disallow: /useless_file.html
Cho phép truy cập vào một trình thu thập dữ liệu
Chỉ Googlebot-news mới có thể thu thập dữ liệu trên toàn bộ trang web.
- User-agent: Googlebot-news
- Allow: /
- User-agent: *
- Disallow: /
Chặn một hình ảnh cụ thể khỏi Google hình ảnh
Ví dụ: không cho phép hình ảnh dogs.jpg.
- User-agent: Googlebot-Image
- Disallow: /images/dogs.jpg
Không cho phép thu thập dữ liệu một thư mục và nội dung trong đó
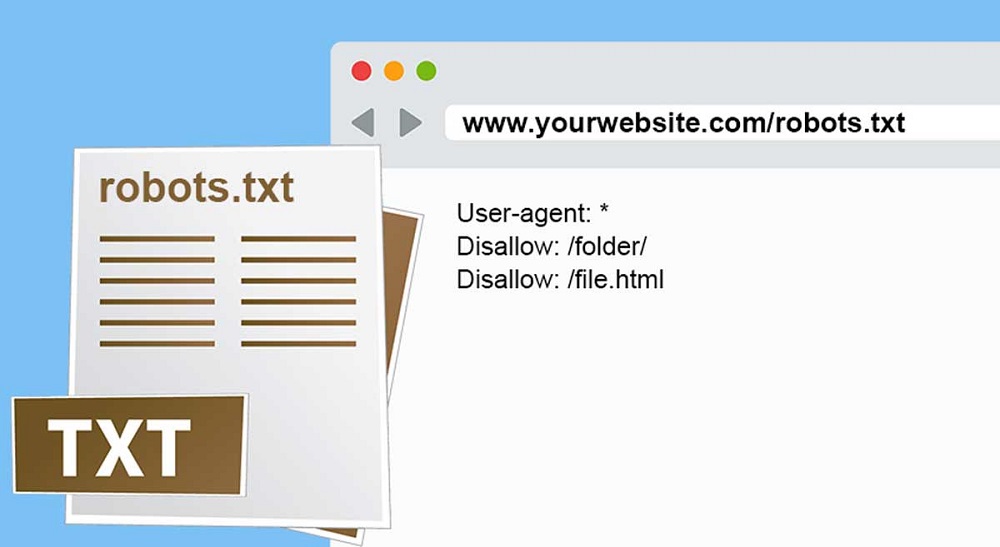
- User-agent: *
- Disallow: /wp-admin/
- Disallow: /wp-includes/
=> Điều này có nghĩa là cho phép tất cả các loại bot thu thập dữ liệu, chỉ trừ hai thư mục wp-admin và wp-includes.
Sử dụng đồng thời “Allow” và “Disallow” cùng nhau
- User-agent: Googlebot
- Disallow: /hoc/
- Allow: /hoc/bai-giang.html
= > Có nghĩa là chặn Googlebot truy cập vào tài nguyên có trong thư mục “hoc” .Nhưng chỉ có thể truy cập file “bai-giang.html”
Một số lưu ý khi sử dụng file Robots.txt
Khi sử dụng lại một Robots.txt của ai đó hoặc tự tạo một Robots.txt riêng cho Website của mình. Bạn cần lưu ý những điều sau đây:
- Phân biệt chữ hoa chữ thường.
- Không nên chèn thêm bất kỳ ký tự nào khác ngoài các cú pháp lệnh.
- Mỗi một câu lệnh nên viết trên 1 dòng.
- Không được viết dư, thiếu khoảng trắng.
Kết luận
Mục tiêu cuối cùng khi sử dụng file Robots.txt đó là cho phép công cụ tìm kiếm crawl những thứ thực sự cần thiết trên Website và disallow một số page không cần thiết. Hãy tự tối ưu và lựa chọn những gì cần thiết trên cho trang web của bạn nhé. Tôi hy vọng bài viết này giúp bạn hiểu và tạo file Robots.txt tối ưu cho SEO. Nếu có bất kỳ thắc mắc hoặc câu hỏi hãy để lại ở dưới nhé!